














Chaque génération de codec, liée à une résolution d’image, élargit la palette des outils de traitement en fonction de la puissance offerte par les circuits intégrés ou les ordinateurs. Pour les codecs exploités en diffusion, tant broadcast qu’en streaming, mais aussi pour une bonne part des outils de production, la technologie la plus performante reste basée sur la transformée de Fourier de type DCT (Discrete Cosinus Transform) associée à une palette d’outils de prédiction spatiale et temporelle de plus en plus étendue. En réalité, depuis les premiers codecs, l’architecture générale d’un codec de type DCT reste la même dans les grandes lignes et ce sont des améliorations constantes au niveau des outils de prédiction et du découpage de l’image en unités de traitement – les blocs – qui offrent des gains d’efficacité. Comme l’expliquait Pascal Massimino, développeur chez Google et qui travaille sur le codec AV1, au cours d’une conférence Paris Video Tech : « Il ne faut pas croire qu’on gagne 10 % en se levant un matin. On grappille à chaque fois 1 ou 2 % avec chaque outil ajouté. Et c’est leur combinaison qui fournit un gain global de 30 ou 40 % par rapport à un codec plus ancien. »
Pour la mise au point du codec AV1, l’alliance AOM a examiné plus d’une centaine d’outils de traitement et en a retenu une soixantaine dans l’architecture finale. Ce travail de dentelle rend le fonctionnement des codecs récents (et leur compréhension) de plus en plus en complexe. Jérôme Vieron, directeur de la Recherche et de l’Innovation chez Ateme confie que « les codecs de compression vidéo sont parmi les programmes les plus complexes de tout l’univers du numérique ».
Pour les diffuseurs de contenus en VOD, les enjeux sur les débits et donc la taille des fichiers sont primordiaux, car chaque programme est reproduit en multiples versions selon les codecs, les tailles d’affichage, le type de terminaux (on cite des chiffres de plusieurs centaines de versions pour un programme unique), elles-mêmes répliquées dans tous les data centers des services de CDN et des FAI autour de la planète. Un gain même minimal de quelques pourcents sur le débit d’un flux vidéo a une incidence financière directe sur le coût des services de VOD et leur équilibre économique.
Élargir la palette d’outils
Au fil des versions, l’architecture des codecs s’enrichit de nouveaux outils et élargit les possibilités des process déjà implantés. La standardisation est impérative pour garantir une interopérabilité entre les diffuseurs et la multitude des systèmes de réception. Contrairement à de nombreux standards dans lesquels tous les paramètres sont figés dès leur publication, les codecs de compression vidéo non propriétaires sont organisés autour d’une architecture et d’une toolbox (boîte à outils) qui est définie lors de la publication du standard, mais dans laquelle les fabricants d’encodeurs ont une relative latitude pour en optimiser le fonctionnement.
L’un des points essentiels de l’organisation des codecs est la syntaxe avec laquelle l’encodeur décrit au décodeur les paramètres de fonctionnement. Lors du lancement d’un nouveau standard de codec de compression vidéo, seule une partie des outils sera mise à profit lors des premières utilisations. Au fur et à mesure des développements et des tests réels, les fabricants vont optimiser les réglages de chaque module et mettre en œuvre des process prévus dans le standard, mais non exploités au démarrage. Au fur et à mesure des développements et de la montée en puissance des circuits électroniques, les performances du codec vont s’améliorer et des débits plus faibles en sortie seront possibles. Jérôme Vieron explique que « chez Ateme, nous continuons à améliorer les performances du Mpeg-2 pourtant lancé en 1994 ».
Cette souplesse dans la configuration d’un codec de compression facilite son adaptation aux multiples usages (production, diffusion TV, streaming, VOD, communication…) mais du coup rend difficile les comparaisons. Il paraît présomptueux de prétendre que tel codec est meilleur qu’un autre. C’est par rapport à une situation explicite et avec une séquence de référence identique, que l’on pourra préciser ses avantages ou ses faiblesses. D’autant que les profils de réglages dépendent énormément des applications. La diffusion d’un programme live diffusé en broadcast exigera un traitement rapide avec un débit en général fixe (CBR) et donc le nombre d’outils mis en œuvre sera plus limité que pour la préparation d’un contenu diffusé en VOD. Dans ce dernier cas, le temps de traitement sera moins critique et l’on cherchera avant tout à limiter le débit tout en préservant la qualité visuelle. Il n’est pas rare de constater un écart de 40 % entre les deux usages pour un codec identique.
Associer techniques de compression et outils de prédiction
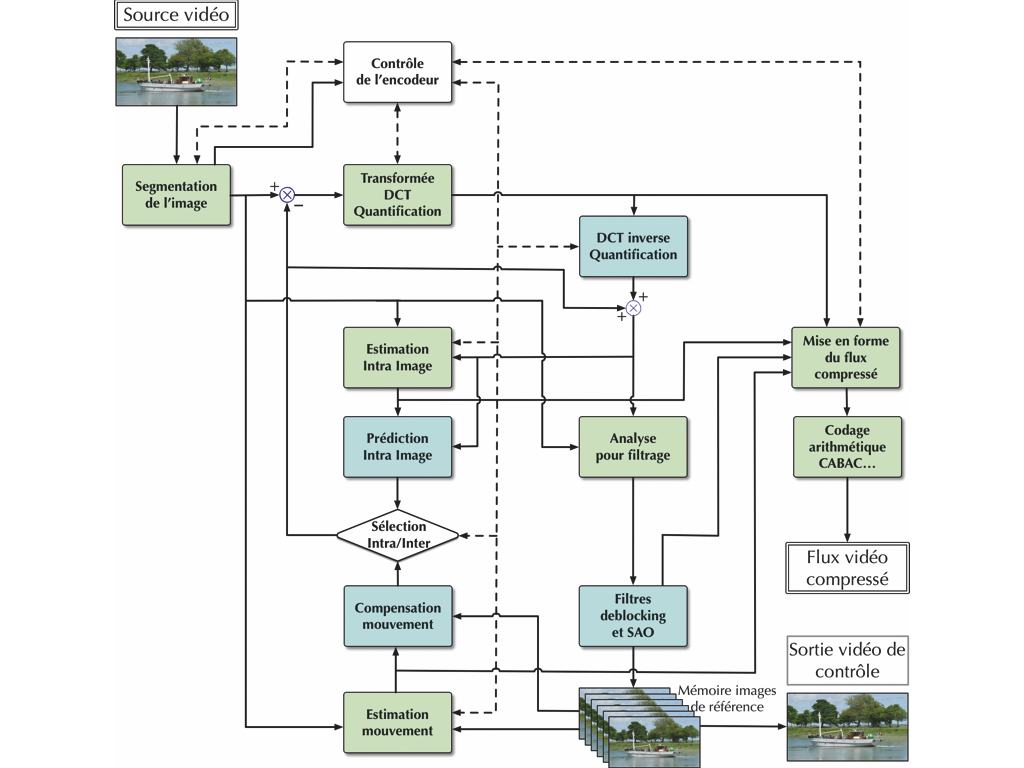
La première étape dans la compression d’un signal vidéo consiste à découper chaque image avec des blocs carrés de pixels qui servent de base aux traitements suivants. Jusqu’au Mpeg-4, ces blocs, dénommés macroblocs, faisaient une taille de 16 par 16 pixels. Avec une résolution quatre fois plus élevée, conserver cette taille aurait fait exploser le nombre de blocs à traiter et donc les temps de traitement. Dans HEVC, cette notion de macrobloc a été transformée en CTU (Coding Tree Unit) avec une taille maximale de 64 x 64 pixels (les tailles de 32 x 32 et 16 x 16 restant possibles). Chaque CTU regroupe les informations de luminance et de chrominance réparties dans des CTB (Coding Tree Block), de taille identique pour la luma et quatre fois plus petits pour les deux blocs de chroma. Mais ces CTB peuvent être trop grands pour un travail optimal des outils de prédiction, en particulier dans les détails fins ou les mouvements rapides. Il est donc possible de les découper en Coding Blocks (CB) dans des tailles plus petites jusqu’à des valeurs de 8 x 8 pixels. C’est à ce niveau que sera décidé d’opérer un traitement de prédiction spatiale (ou intra-image) ou temporelle (interimage). La taille de ces blocs pourra encore être réduite lors de ces traitements avec des valeurs différentes pour le traitement intra ou inter. Leur découpage pourra être asymétrique pour tenir compte du sens de répétition des données. Ces principes de découpage en sous-blocs, selon un mode quad-tree, développés lors de la conception du H.265 sont repris dans le codec AV1 et le futur JVET, mais avec des valeurs et modalités différentes. Ensuite les outils de prédiction, spatiaux ou temporels, sont mis en œuvre pour trouver un Coding Block similaire à celui pris en référence, dans l’image elle-même ou dans une image précédente. Il y a peu de chances que les deux blocs soient strictement identiques. Mais les informations du vecteur de déplacement du bloc et l’écart de données entre les deux, appelés résidus, sont souvent plus légers qu’une nouvelle transmission du bloc. C’est au niveau de ces outils de prédiction que de nombreux progrès sont apportés au fil des différentes versions de codecs. Les ingénieurs multiplient les modes d’interpolation et élargissent le nombre de vecteurs possibles. Dans le codec AVC H.264, il était prévu neuf types de vecteurs d’interpolation intra. Ce chiffre passe à 33 pour le H.265, il est fixé à 14 pour l’AV1 et il est envisagé 65 vecteurs pour le futur JVET/H.266. Un tableau comparatif publié dans le Mediakwest #26 page 77 fournit des détails sur les outils choisis pour chaque standard.
Pour éviter les ruptures au niveau des limites de blocs, les outils de prédiction tiennent également compte des valeurs des blocs voisins. Selon le type de plans et des mouvements dans l’image, le process sélectionne soit les valeurs de prédiction intra-image ou interimages. La première image d’une séquence ou les images clés pour un accès aléatoire au contenu sont toujours traitées en mode intra et ne dépendent pas des images voisines. Les valeurs de résidus ou des blocs sont ensuite envoyées vers un second processus de réduction de débit basé sur la transformée de Fourier en Discrete Cosinus Transform. Ce traitement mathématique consiste à réorganiser des données spatiales réparties sur les pixels du bloc en données fréquentielles. Comme il s’agit de compresser des images réelles, les valeurs de pixels varient lentement et correspondent à des valeurs fréquentielles relativement basses qui se retrouvent principalement dans la partie supérieure gauche du bloc. La réduction de débit apportée par la DCT est déjà réelle, mais il est possible d’aller encore plus loin en réduisant le pas de quantification. Les valeurs les plus faibles dans le quart inférieur droit sont éliminées, mais, c’est là la force de la DCT, lors de la transformation inverse, les valeurs reconstruites ne bougeront que très légèrement et les variations de niveau seront respectées.
Une segmentation de l’image plus élaborée
Toujours dans l’optique d’optimiser le débit et le process de traitement, les ingénieurs exploitent aussi des modes d’association des blocs CTU pour les regrouper dans des unités plus grandes, les « tiles » (carreaux) et les « slices » (tranches). Une tile regroupe plusieurs blocs CTU dans une forme rectangulaire ou carrée pour découper l’image en grandes zones. Dans la même tile, les CTU partageront les mêmes informations de codage de façon à permettre un traitement en mode parallèle. Les slices regroupent des CTU contigus, mais dans des formes plus libres (jusqu’à une image complète) de manière à optimiser la charge utile par rapport à la taille MTU des paquets du réseau. Cela permet de remplir au mieux les paquets, de réduire la latence (une slice pouvant être transmise alors que la suivante est encore en cours d’encodage) et de resynchroniser plus facilement la reconstruction de l’image en cas de perte de données. L’implantation et la configuration des tiles et des slices varie de manière importante selon les codecs et leurs évolutions.
Tous les encodeurs de compression vidéo possèdent également les outils de décodage. En effet, les process de prédiction sont basés sur une comparaison entre l’image traitée et une image précédente du flux vidéo. Lors du décodage le contenu de l’image est reconstruit à partir de cette image précédente avec les éléments de prédiction et les résidus. Dans le décodeur, l’image qui sert alors de référence aura vu son contenu traité par la DCT et la quantification, ce qui altère légèrement la valeur des pixels. Si, dans l’encodeur, on utilise comme référence l’image d’origine avant traitement DCT, les résidus calculés seront différents de ceux obtenus dans le décodeur. Il en résulte une légère erreur qui va s’accumuler au fil du flux vidéo. Il est donc indispensable de prévoir, dans l’encodeur, les circuits de décodage pour effectuer les prédictions dans des conditions identiques à celles du décodeur. Une mémoire (ou buffer) va stocker ces images décodées pour qu’elles servent d’images de référence. Selon la résolution et le type de codec, le nombre d’images stockées varie entre trois et seize. Lors de cette phase de décodage, une série de filtres est appliquée pour atténuer les effets de bordure entre les blocs et réduire les défauts au niveau des transitions colorées (bourdonnement, irisation…).
L’ajout de toutes ces fonctions et des méthodes d’analyse et de prédiction rend extrêmement complexe l’architecture des codecs récents. Les faire évoluer demande de reprendre le travail de standardisation dans le cadre d’un long processus d’échanges et de discussions. La pression des diffuseurs et des nouveaux services OTT pousse leurs concepteurs à grappiller quelques centaines de kilobits, mais en restant dans le cadre de l’architecture dénie dans le standard. C’est pourquoi ils explorent d’autres méthodes d’optimisation, soit à l’intérieur même de l’encodeur avec un traitement en mode multipasses.
Paramétrer l’encodeur selon le contenu
Si les paramètres de l’encodage sont fixés une fois pour tous les programmes, le débit résultant ne sera pas optimisé et le service de VOD ne profitera pas de toutes les potentialités du codec. Les diffuseurs ont souhaité aller plus loin pour affiner les paramètres en fonction du contenu du programme, avec des plans plus ou moins détaillés, la texture de l’image, la rapidité des mouvements, la stabilité du cadrage… Fixer une valeur au débit en fonction uniquement de la résolution du récepteur conduit à trop de rigidité avec le risque d’avoir quand même des défauts pour les images très complexes et au contraire utiliser un débit trop élevé et des fichiers trop lourds pour des films plus statiques.
Les résultats d’un même encodage donneront des résultats fort différents pour un dessin animé, un film romantique ou un western. Netflix a lancé des séries de tests en encodant cent films avec quatre profils d’encodage et a reporté les mesures de débit et du niveau de qualité grâce à la mesure du PSNR. On constate une énorme dispersion des résultats, et qu’au-delà de certains niveaux de qualité, celle-ci n’augmente plus avec le débit. Cela leur a permis de définir des profils de débit adapté à trois tailles d’affichage : haute résolution, moyenne et basse. Ces trois courbes sont regroupées dans une enveloppe convexe (Convex Hull) qui sert à fixer les jeux de paramètres d’encodage pour ces trois résolutions. Ces valeurs sont déterminées à partir de mesures du niveau de qualité, d’abord en PSNR (Peak Signal to Noise Ratio), mais ce système ne rend pas compte de tous les défauts visibles qui peuvent encore subsister. La mesure du SSIM (Structural Similarity Index) lui est préférée et Netflix a en outre développé son propre outil, le VMAF (Video Multimethod Assessment Fusion). Tous ces travaux l’ont conduite à mettre en place une procédure d’encodage par titre et d’adapter ainsi les paramètres de l’encodeur à chaque contenu de films ou de séries.
Il est évident que ce processus ne peut pas être mené de manière manuelle, compte tenu du volume de programmes inscrits au catalogue des services de VOD. D’autres diffuseurs ont exploré des méthodes de classification par genres : films d’action, dessins animés, sports, comédies, talk-shows, pour leur appliquer des profils adaptés. Mais même à l’intérieur d’une catégorie, la disparité des contenus et des types de plans peut être encore fort large et cette méthode ne donne pas des résultats pertinents pour des services premium. Cette méthode est plutôt appliquée par des sites de diffusion spécialisés dans une catégorie de programmes et où la diversité des plans est moins étendue, par exemple des sites corporate ou de formation, donc moins grand public.
Cette prise en compte de la diversité des programmes pour fixer les paramètres de la compression peut être reprise avec une approche encore plus fine au niveau des plans. Au cours d’un même film, les séquences s’enchaînent avec des cadrages, des rythmes ou des mouvements de caméras fort divers. Là aussi il est possible d’ajuster à chaque fois les jeux de réglages de l’encodeur pour optimiser le débit et préserver la qualité des images en restant dans des valeurs encadrées. De nombreux spécialistes de l’encodage développent cet axe de recherche en proposant des outils regroupés sous le terme générique de « content aware » ou de « content adaptative ». Les plus avancés explorent le potentiel apporté par les recherches menées autour de l’intelligence artificielle.
Associer des outils de performances psycho-visuelles
Ainsi BeamR a conçu un outil de réencodage d’un fichier vidéo compressé. Il est basé sur une boucle de réaction avec comparaison entre le nouveau flux encodé et la source initiale déjà encodée une première fois. Chaque image, décodée et réencodée avec des paramètres ajustés, est analysée avec des outils de perception de qualité visuelle brevetés. Deux seuils de qualité ont été fixés. Si la note de qualité est supérieure à la valeur maximale, l’image initiale est réencodée avec des paramètres plus sévères offrant un débit plus faible. Si elle est inférieure à la valeur minimale, l’image est réencodée avec des valeurs plus favorables pour éviter la perte de qualité perceptible. Pour les images avec une qualité située entre les deux seuils, elle est validée et envoyée ensuite vers l’agencement des divers flux de streaming. Les gains, en termes de débits, varient selon la résolution des images et le type de contenus. Ils se situent, d’après le concepteur, dans une fourchette comprise entre 10 et 45 %.
De son côté, Harmonic a mis au point un système dénommé EyeQ. Il fonctionne également sous forme d’une boucle de réaction dans l’encodeur lui-même. Harmonic a conçu cet outil pour ses encodeurs H.264 et propose ainsi à ses clients une amélioration des débits vidéo sans passer par un remplacement des installations en place par la version H.265. Le constructeur très proche des diffuseurs broadcast prend en compte les contraintes liées aux évolutions techniques des parcs importants de décodeurs largement distribués. Il base son process sur les principes de la perception visuelle humaine (HVS) en analysant la nature des diverses zones de l’image, en tenant compte du fait que la vision humaine est plus sensible à des changements de contraste plutôt qu’à des différences de luminances, plus réceptive à des mouvements qu’à des textures… et bien d’autres éléments. Il effectue une pondération entre l’importance de chaque critère dans la perception de la qualité et leur incidence sur le débit. Les résultats de ce process agissent directement sur les paramètres de la compression. Avec cette fonction EyeQ, il affirme pouvoir réduire le débit vidéo de 50 %.
Le spécialiste français Ateme travaille également sur des outils pour optimiser l’encodage en fonction du contenu. À partir de techniques de « machine learning » et de modèles psychovisuels propriétaires, il a développé ses propres outils de mesure de la perception visuelle, regroupés sous le terme AQI (Ateme Quality Index). Basés sur l’analyse spatiale et temporelle des macroblocs, ils fournissent une prédiction du niveau de qualité perçue et du débit. Cette méthode est validée par des mesures a posteriori sur des séquences réelles. Une pré-analyse du flux vidéo fournit les données AQI du contenu, qui agissent sur les paramètres de l’encodeur avec l’objectif de réduire le débit tout en préservant le niveau de qualité perçue par le spectateur. Ateme s’appuie sur une large base de données de résultats réels pour optimiser les valeurs en fonction du codec et de la résolution. Pour tenir compte des variations de contenu du programme, Ateme applique cette méthode plan par plan et redécoupe les chunks (tronçons), indispensable dans toute procédure de diffusion en streaming adaptatif, aux coupes de montage. Cette procédure optimise le débit vidéo final à sa juste valeur (ni trop, ni trop peu) par rapport au contenu réel du plan. D’après différents tests, elle offre une réduction de débit de l’ordre de 10 à 50 % par rapport aux valeurs d’un encodage de type CBR. Le gain dépend beaucoup du type de programmes et de la variété des images qui les composent.
Ce rapide panorama des récentes évolutions techniques dans l’architecture des codecs de compression vidéo montre qu’au-delà de l’arrivée de nouveaux standards comme l’AV1 ou le futur JVET/H.266 qui se déroulent sur ces cycles longs de plusieurs années, les constructeurs et les diffuseurs travaillent sans cesse sur l’amélioration des codecs existants pour accroître leurs performances et surtout réduire les débits et les tailles de fichiers.
* Article paru pour la première fois dans Mediakwest #27, p. 106-109. Abonnez-vous à Mediakwest (5 numéros/an + 1 Hors-Série « Guide du tournage ») pour accéder, dès leur sortie, à nos articles dans leur intégralité.



















